Objects that Sound
Authors: Relia Arandjelović and Andrew Zisserman (DeepMind, VGG Oxford)
时间: 2017-12
链接: https://arxiv.org/abs/1712.06651
1 Introduction
本文旨在通过利用无标签视频中的视听对应关系 (Audio-Visual Correspondence, AVC) 作为训练目标,实现两个主要目标:
1. 学习能够将音频和视觉输入嵌入到公共空间中的网络,适用于跨模态检索 (Cross-modal retrieval)。
2. 仅给定音频信号,在图像中定位发声物体 (Localizing the object that sounds)。
这种方法属于一种自监督学习 (Self-supervision),利用视频本身提供的自然同步信号(同一时间的帧和音频为正样本,不同视频的为负样本)来构建训练标签。
3 Cross-modal retrieval
为了实现跨模态检索,作者提出了 AVE-Net (Audio-Visual Embedding Network)。
Method
AVE-Net 的核心设计思想是直接优化视觉和音频的嵌入表示,使其欧氏距离能够反映两者的对应关系。
- Vision Subnetwork: 处理图像输入,提取视觉特征。
- Audio Subnetwork: 处理1秒钟的音频(对数声谱图),提取音频特征。
- Feature Fusion: 两个子网络分别输出 $128$-D 的 $L2$ 归一化嵌入向量。
- Correspondence Score: 计算两个嵌入向量之间的欧氏距离,并通过一个微小的全连接层(FC)进行缩放和移位,最终通过 Softmax 输出对应/不对应的概率。
数学上,设视觉嵌入为 $f_v(I)$,音频嵌入为 $f_a(A)$,则网络优化的目标是使得对于匹配对 $(I, A)$,欧氏距离 $\|f_v(I) - f_a(A)\|_2$ 较小,而对于不匹配对则较大。
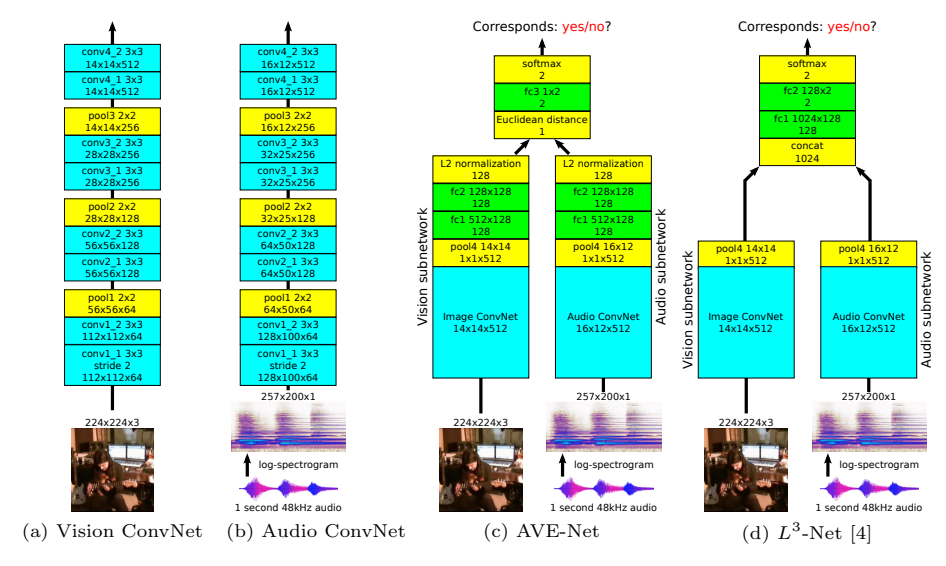
Figure 2: ConvNet 架构对比。(c) AVE-Net 明确利用嵌入之间的欧氏距离来判断对应关系,强制特征在公共空间对齐。(d) 对比 $L^3$-Net [4],其通过拼接特征后接 FC 层来判断,导致特征未在嵌入空间显式对齐,不适合检索。
Results
在 AudioSet-Instruments 数据集上,AVE-Net 在跨模态检索(以图搜音、以音搜图)任务上显著优于基线方法(包括 $L^3$-Net 和基于 ImageNet 预训练特征的方法),证明了通过 AVC 任务学习到的嵌入具有良好的语义判别性。
4 Localizing objects that sound
为了回答“图像中哪个物体在发声?”这一问题,作者提出了 AVOL-Net (Audio-Visual Object Localization Network)。
Method
定位问题被建模为 多示例学习 (Multiple Instance Learning, MIL) 问题。
-
Vision Subnetwork 修改:
- 移除了最后的全局池化层,保留 $14 \times 14$ 的空间分辨率。
- 将全连接层转换为 $1 \times 1$ 卷积层。
- 输出为 $14 \times 14$ 的特征图网格,每个位置对应一个 $128$-D 的局部描述符 $v_{i,j}$。
-
Audio Subnetwork:
- 保持不变,输出一个全局的 $128$-D 音频描述符 $a$。
-
Similarity Map:
- 计算音频向量 $a$ 与每个位置的视觉向量 $v_{i,j}$ 的点积(标量积),得到 $14 \times 14$ 的相似度图 (Similarity Score Map) $S_{i,j} = a^T v_{i,j}$。
- 这一步实际上是将音频表示作为一个滤波器(Filter),在图像特征图上寻找响应最高的区域。
-
Training Objective:
- 使用 Max Pooling 聚合空间上的分数,取最大值作为整张图像与音频的对应分数:$s = \max_{i,j} S_{i,j}$。
- 训练目标仍然是 AVC 任务。对于正样本,网络被鼓励在图像的某个区域(发声物体所在处)产生高响应;对于负样本,所有区域的响应都应较低。
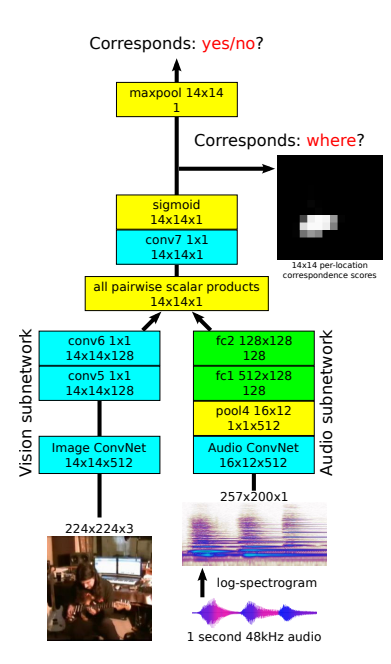
Figure 4: AVOL-Net 架构。视觉网络保留空间结构,音频特征作为卷积核与视觉特征图进行点积,生成定位热力图。最大值被用于计算损失,从而实现弱监督定位。
Results
AVOL-Net 能够在没有边界框监督的情况下,仅通过视听对应任务,成功定位发出声音的物体(如乐器、歌手嘴部等)。

Figure 5: AVOL-Net 的定位结果。网络仅凭单帧图像和对应的音频,就能定位出图像中发声的区域(如钢琴键盘、吉他等),且不受运动信息干扰(输入为单帧)。
5 Conclusions
本文展示了无监督的视听对应任务(AVC)不仅可以用于学习强大的跨模态语义嵌入(AVE-Net),还可以通过多示例学习框架(AVOL-Net)实现精细的声源定位。这种方法完全不依赖人工标签,仅利用视频中天然的视听同步信息。